Large language models are not zero-shot communicators
Authors. Laura Ruis, Akbir Khan, Stella Biderman, Sara Hooker, Tim Rocktäschel, Edward Grefenstette.
TL;DR. Understanding of pragmatics is an essential and ubiquitous part of human communication. We show large language models (LLMs) mostly don’t capture this aspect of language zero-shot, hindering their applicability in the real world. Our analysis indicates where the largest room for improvement is to ultimately make this technology more useful.
Paper. ArXiv
Code. GitHub
Dataset. Uploaded with prompt templates on HuggingFace
Introduction
Recently, a large language model (LLM) called LaMDA beautifully passed (a variation of) the Turing test. In our most recent paper’s title we state that LLMs are not zero-shot communicators. What gives? How can these two things both be true? What do we mean by “communicators”? In this post I’ll motivate the statement by summarising the paper’s results.
Consider the following exchange between a human and InstructGPT.
User: “Have you seen my phone?”
InstructGPT: “Yes, I have seen your phone.”
InstructGPT can understand the syntax and semantics of the question perfectly, produce a high-likelihood response, and still miss the meaning of the question entirely. Language models can be fluent–even fooling people into thinking they’re conscious–but still miss an important aspect of language understanding. Indeed, this question has a pragmatic implication; an inquiry about the location of a phone. Humans use commonsense knowledge like an experience of having lost their own phone in the past to infer that the speaker is probably looking for it instead of actually wanting a yes-no response. This illustrates an essential and ubiquitous aspect of our every day usage of language: interpreting language given the context of our shared experience. In this work, we uncover a failure mode of LLMs when the task requires interpreting language in context.
Let’s start with the main message of the paper.
Main message
Main result. Pragmatic language understanding is key to communicating with humans and all large language models we tested fall short on a very simple test of it.
Finding. A promising path forward seems to be instruction-finetuning; instructable models perform significantly better than all others zero-shot and can be prompted with in-context examples to get close-to-human performance.
Finding. However, even the best instructable model we tested leaves a significant gap with human performance on a subset of the data that requires context to be resolved, even in the few-shot case.
Future work. There is ample room for improving the pragmatic understanding skills of LLMs. Additionally, since we test very simple utterances, future work can design more complex tests of pragmatic understanding.
Takeaway. LLMs can make large improvements in communication skills if we shift focus from syntax and semantics to pragmatic language understanding.
Defining communication
We believe the next big step forward for LLMs is improving their understanding of pragmatic language – viewing language as a collaborative, communicative effort influenced by context. Indeed, the distinction between communication and fluent text generation is precisely pragmatic understanding1. Successful communication requires the speaker’s implications to be understood by the addressee. Our everyday language is riddled with implicated meaning determined by context; almost every conversation will contain examples of it. Consider again an exchange, taken from the dataset used in this paper:
Esther: Did you leave fingerprints?
Juan: I wore gloves.
This example uses the context from the physical world that we cannot leave fingerprints when wearing gloves. Without knowing this, the response is seemingly arbitrary. It is an example of an implicature: an utterance conveying something other than its literal meaning (in this case “no, I did not leave fingerprints.”).
Communication is a collaborative effort where speakers try to convey intentions to each other. A “communicator” can successfully infer the hidden implications in conversation by tapping into their own belief systems, the speaker’s belief system, common history, commonsense knowledge, and more. All this can be grouped under the term context. Importantly, the way we use the term here is not to be confused with the way its often used in NLP: the literal semantic context around an utterance. On the contrary, the type of context we are referring to here is generally not explicitly part of a conversation. Pragmatic analysis goes beyond syntax and compositional semantics of utterances, instead looking at how context determines meaning.
To see a more in-depth introduction of implicature refer to Appendix B of our paper. Also, check out concurrent theoretical work by DeepMind researchers emphasising the importance of pragmatic language understanding for value alignment.
Evaluating Large Language Models
To evaluate pragmatic language understanding we subject a set of SOTA LLMs to an implicature resolution test. To this end, we use a dataset of conversational implicatures2 like the following.
Esther: Want to stay for a nightcap?
Juan: I’ve gotta get up early.
The implicated meaning of Juan’s response is “no”. We say a language model “understands” this implicature if it assigns a higher likelihood to the meaning of the response. Schematically:
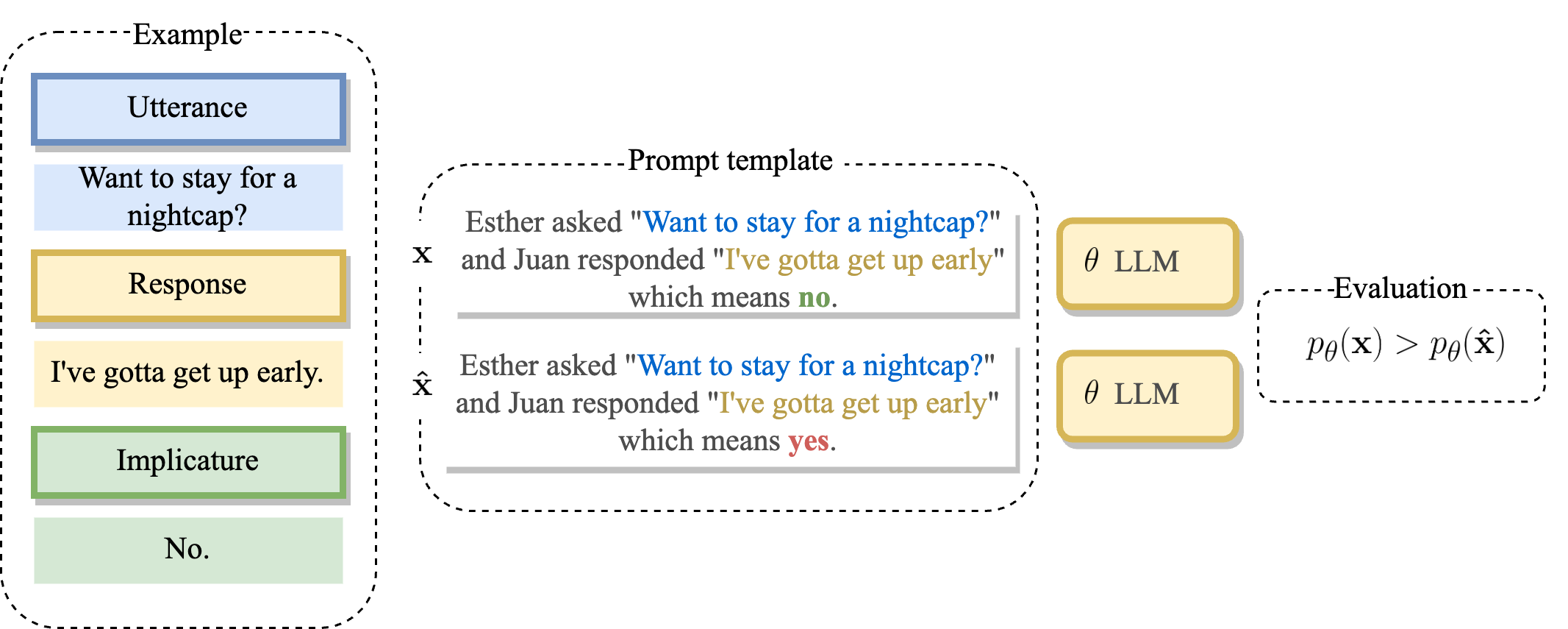
This protocol is applicable to likelihood-based language models out-of-the-box. All examples in the dataset we use resolve to a simple “yes” or “no”. We use a set of prompt templates (6 in total, 1 showing above) to accommodate LLMs known to be sensitive to prompt wording. We separate the dataset into a test and development set and use the latter for few-shot in-context prompting. In an attempt to push the zero-shot performance of the best performing models we further test them with three instruction prompts recently used by researchers at DeepMind for their model Sparrow 3. For example:
Instruction prompt
The following text shows an interaction between two humans called Esther and Juan.
In the interaction, Esther will ask Juan a question, and Juan will give an answer that has a meaning besides the literal meaning of the words.
That meaning is either yes or no.
You, a highly intelligent and knowledgeable AI assistant, are asked to finish the text with the correct meaning, either yes or no.
The task begins:Esther asked “Want to stay for a nightcap?” and Juan responded “I’ve gotta get up early”, which means
Sneak-peak into the results
For all the results, check out the paper. Here I’ll briefly summarise the main findings.
The set of large language model classes we evaluate can be grouped into four distinct categories:
(1) base models: RoBERTa, BERT, GPT-2, EleutherAI, BLOOM, OPT, Cohere, and GPT-3 (solid lines in plot below)
(2) LLMs finetuned on dialogue: BlenderBot (dotted line in plot below)
(3) instructable LLMs finetuned on downstream tasks: T0 and Flan-T5 (dashed lines below)
(4) instructable LLMs finetuned with an unknown method: OpenAI’s latest InstructGPT-3 series (dash-dot line below, i.e. text-<engine>-001, and text-davinci-002)
Each group contains one or more model classes for which we evaluate a range of model sizes. Random performance on the dataset is 50% accuracy, humans obtain on average 86.2% accuracy, and the best humans obtained 89%.
Zero-shot results
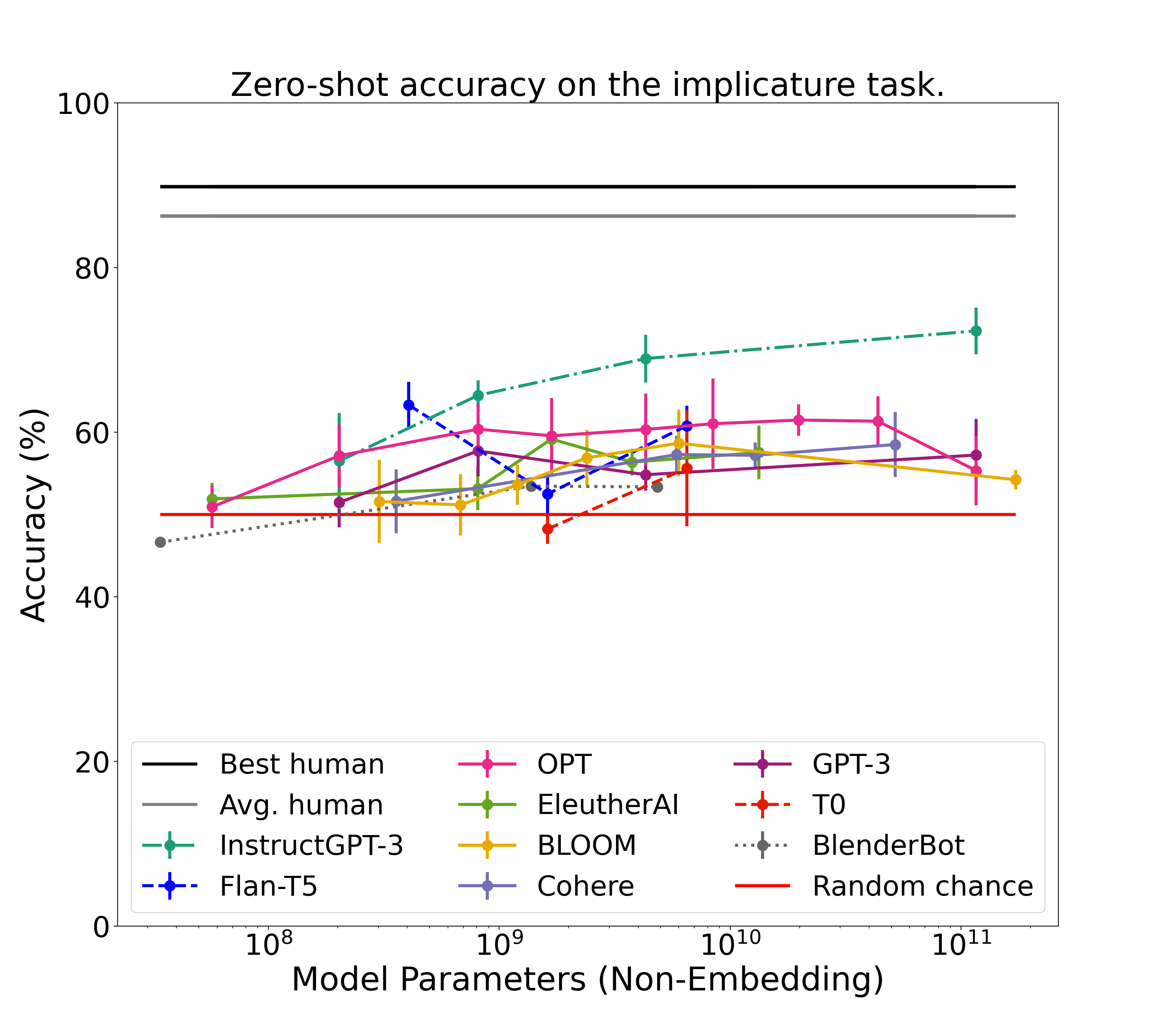
OpenAI’s instructable models are the best model classes we look at, with InstructGPT-3-175B obtaining 72% zero-shot accuracy. This leaves a gap of 13.9% with human performance. The best models of the other classes we look at achieve between 53.4% (BlenderBot-2.7B) and 63.3% (Flan-T5-780M) zero-shot accuracy.
Surprisingly, most models end up with a slope close to zero or even below zero. The only model classes for which the largest model actually does best are InstructGPT-3, Cohere, and T0. For GPT-3 the 1.3B parameter model does better than the 175B one (although marginally), and for Flan-T5 the smallest model of the class outperforms all others!
For details see the paper: section 4.1, Figure 2 left, Table 1
Side notes. There is a lot more to unpack in this plot, much of which we did not get into in the main paper, if only because it’s hard to draw conclusions. For example, we cannot say why InstructGPT-3 does better than other models, we have no idea about the method used to train this model. Additionally, what is going on with that Flan-T5 curve? Why do some model classes peak in performance with a smaller model than their largest? What would happen if we scale up even further? And how would models like Chinchilla, PaLM, and LaMDA perform? All open questions.
Additional instruction prompts
Perhaps we can improve the zero-shot performance of the best models with better prompting?
For the three OpenAI models (GPT-3, InstructGPT-3-175B, and text-davinci-002) we attempt the zero-shot experiment again, but now with three more elaborate prompts containing detailed instructions (see the instruction prompt introduced above). It does not help.
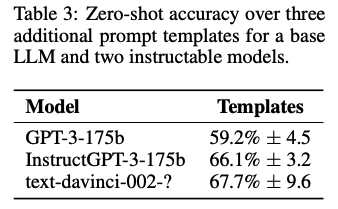
For details see the paper: section 4.1
In-context prompting
We use the original 6 prompt templates, but now add in-context examples. At \(k=30\) we find that performance jumps to 80.6% for text-davinci-002, which is near-human performance! It does not help much for the other models.
Additionally, which (type of) prompt template works best is different for each model class, and which benefits most from in-context prompting as well. Below we see the relative accuracy increase over zero-shot for InstructGPT-3-175B, Cohere-52B, and OPT-175B.
Template 2, 5, and 6 are natural prompt templates (dotted lines above) and are similar to the ones we’ve already introduced above, e.g.
Esther asked “Want to stay for a nightcap?” and Juan responded “I’ve gotta get up early”, which means no.
Template 1, 3, and 4 are structured prompt template (dashed lines above) has a form like:
Question: Want to stay for a nightcap?
Response: I’ve gotta get up early.
Meaning: No.
We see in the plot above that InstructGPT-3-175B benefits relatively equally from in-context prompting for each prompt template, whereas Cohere-52B is better at natural prompts zero-shot and mostly benefits from in-context prompting for structured prompts and OPT-175B vice-versa.
For details see the paper: section 4.2, Figure 2 right, Figure 4
Still a significant gap with humans on context-heavy examples
We manually labeled a part of the dataset according to a taxonomy that distinguishes context-free and context-heavy examples. An example of a context-free implicature is the following:
Esther: You know all these people?
Juan: Some.
It is an implicature4, because the hidden meaning we can infer is that Juan does not know all the people. However, we do not need context to resolve it, the implicature is resolved by the conventional meaning of the word some. The nightcap example used earlier in this post is an example of a context-heavy example.
Esther asked “Want to stay for a nightcap?” and Juan responded “I’ve gotta get up early”, which means no.
We need the contextual commonsense knowledge that having to work early the next morning usually means we do not want to go drinking the night before.
We find that humans obtain 83.2% accuracy on context-heavy examples and the best performing model obtains an accuracy of 59.7% zero-shot. This increases the zero-shot performance gap between the best performing model and humans to 23.5%. Again, in-context prompting helps a lot. Still, at \(k=30\) the gap on context-heavy examples is 8.8% for the best performing model (text-davinci-002).
For details see the paper: section 4.1, section 4.2, Table 2, Figure 3
Conclusion
We identify language pragmatics as a crucial aspect of communication that current SOTA LLMs are missing. We evaluate LLMs on a simple test of pragmatics that requires binary resolution and find that they struggle. This opens the door to more complex tests of pragmatic understanding. We are excited about the prospects of large language models becoming “communicators” by improving their pragmatic language skills. You can read about our work in more detail here.
Sources
-
Nicely outlined by G.M. Green, 1996. in Pragmatics and Natural Language Understanding. ↩
-
The data was curated by Elizabeth Jasmi George and Radhika Mamidi, find the paper introducing it here. ↩
-
Amelia Glaese et al, 2022. Improving alignment of dialogue agents via targeted human judgements ↩
-
It is an implicature if you adhere to Gricean definitions, if you read work on pragmatics by other researchers (e.g. Chris Potts), these type of examples are actually resolved fully through semantics and are not considered implicatures (see Appendix B in the paper). ↩